

O problema
OPostagem anteriorem nossa série discutimos técnicas para fornecer privacidade de entrada em sistemas PPFL onde os dados são particionados horizontalmente. Este blog se concentrará em técnicas para fornecer privacidade de entrada quando os dados são Particionado verticalmente.
Conforme descrito em nossoTerceira postagem, o particionamento vertical é onde os dados de treinamento são divididos entre as partes, de modo que cada parte contenha colunas diferentes dos dados. Em contraste com os dados particionados horizontalmente, o treinamento de um modelo em dados particionados verticalmente é mais desafiador, pois geralmente não é possível treinar modelos separados em diferentes Colunas dos dados (mas sobrepostos Linhas) e depois compô-los.
Em vez disso, precisamos de métodos para poder treinar os dados coletivos e, ao mesmo tempo, proteger a privacidade desses dados. Uma etapa crítica necessária para isso é Alinhamento de entidades que preservam a privacidade:Correspondência de registros correspondentes (por exemplo, registros que fazem referência à mesma pessoa) em diferentes conjuntos de dados.As partes podem usar o resultado do alinhamento de entidade para treinar um modelo de maneira semelhante a como fariam em um cenário de particionamento horizontal.
Combinar registros correspondentes sem revelar os registros em si é uma tarefa desafiadora. No restante deste blog, discutimos dois métodos para alinhamento de entidades que preservam a privacidade: interseção de conjunto privado e filtros Bloom.
Interseção de conjunto privado
Um interseção de conjunto privado (PSI)é uma técnica de privacidade de entrada que permite a vinculação de dados entre as partes. O resultado de um processo PSI revela informações aos participantes somente para linhas de dados que correspondem a uma chave comum. Isso é ilustrado na Figura 1. Por exemploum projeto piloto de pesquisa liderado por pesquisadores da Universidade de Georgetown aplicou o PSI para vincular os dados do Departamento de Educação dos EUA com os dados do Sistema Nacional de Dados de Empréstimos Estudantis para calcular estatísticas de ajuda financeira sem revelar os números de previdência social dos alunos.
Crédito:
NIST
Algumas abordagens PSI revelam apenas o número de linhas correspondentes, enquanto outros revelam mais informações (por exemplo, o conteúdo de linhas correspondentes, como no exemplo da Figura 1). Os sistemas PPFL geralmente dependem do conteúdo das linhas correspondentes e, portanto, devem usar abordagens PSI “com vazamento”. Há também algumas compensações a serem consideradas entre a força de uma técnica PSI na proteção de dados contra seu desempenho quando aplicada em cenários de aprendizado federado em grandes conjuntos de dados, como os dos Desafios do Prêmio PETs Reino Unido-EUA.
Filtros de bloom
Uma segunda abordagem para o alinhamento de entidades é construir umFiltro de bloom—Uma estrutura de dados probabilística que usa uma coleção de funções de hash para permitir o armazenamento eficiente e a pesquisa de elementos. Como os filtros de Bloom são probabilísticos, às vezes eles cometem erros (falsos positivos).
No contexto do PPFL, os filtros Bloom podem também fornecer benefícios de privacidade. Especificamente, os falsos positivos fornecem um tipo de proteção de privacidade de entrada automaticamente. Alguns sistemas PPFL usam filtros Bloom para facilitar a preservação da privacidade Mineração de recursos— um processo que determina quais atributos dos dados usar ao construir o modelo. Esta foi a abordagem utilizada pelosPETs escarlates, uma equipe vencedora do lado americano daDesafios do Prêmio PETs Reino Unido-EUA. Sua solução é mostrada na Figura 2.
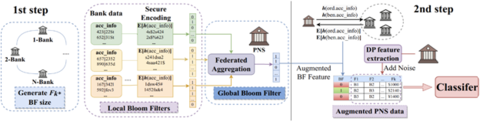
Crédito:
NIST
Na primeira etapa, a mineração de recursos é realizada localmente em cada banco para criar filtros Bloom locais contendo contas consideradas potencialmente suspeitas com base nos dados no nível da conta. Esses filtros locais são agregados em um filtro Bloom global, que é usado para aumentar os dados de transação da rede de pagamento. Como os filtros Bloom são representados como strings de bpodem ser agregados usando as técnicas descritas emNosso quarto post. Por fim, a rede de pagamento adiciona um campo binário adicional “BF” aos dados da transação, que é 1 se a conta de envio ou recebimento da transação estiver presente no filtro Bloom global e 0 caso contrário. Isso conclui a etapa de alinhamento de entidade e um classificador (diferencialmente privado) pode ser treinado nesses dados aumentados.
O uso de filtros Bloom ajuda a proteger a privacidade de entrada, pois não há compartilhamento direto de dados entre as diferentes partes; apenas informações sobre a presença ou ausência potencial de uma característica específica são reveladas, não o conteúdo real dos dados em si. No entanto, ainda pode ser possível que dados confidenciais vazem por meio de um filtro Bloom. No exemplo acima, o filtro Bloom global é compartilhado com oRede de pagamentos. Dependendo da precisão do filtro e de como ele foi construído, pode ser possível que oRede de pagamentos para aprender algumas informações sobre os dados bancários que eles não deveriam. No mínimo, nesta configuração, oRede de pagamentosé capaz de aprender que, para transações em que BF = 1, há uma alta probabilidade de que um dos bancos tenha sinalizado a conta de envio ou recebimento (ou ambas) como suspeita. No mundo real, uma decisão política precisaria ser tomada entre os bancos e oRede de pagamentospara determinar se tal vazamento de dados seria permitido.
Equilibrando desempenho com vazamento
As técnicas descritas neste post fornecem métodos eficientes para realizar o alinhamento de entidades com privacidade de entrada no PPFL, mas ambas vazam algumas informações sobre os dados privados envolvidos. No caso de PSI, o sistema pode vazar informações sobre o número ou mesmo o conteúdo das linhas correspondentes; no caso de filtros Bloom, o sistema vazará informações (ruidosas) sobre o status de correspondência de cada linha. É possível colocar técnicas adicionais em camadas para eliminar esse vazamento, como computação multipartidária segura, criptografia totalmente homomórfica ou enclaves seguros — mas conforme discutidoem nosso quarto post, essas técnicas geralmente têm um custo de desempenho significativo.
Os projetistas de sistemas devem considerar cuidadosamente o vazamento dessas técnicas como parte do Modelo de ameaça– a descrição dos invasores contra os quais o sistema deve se defender. Em alguns casos, o vazamento adicional representa pouco risco de privacidade e pode ser aceitável usar PSI ou um filtro Bloom como parte do sistema. Em outros casos, o vazamento apresenta grandes riscos à privacidade e requer o uso de técnicas adicionais. Equilibrar o risco de privacidade do vazamento de informações com o custo de desempenho da prevenção desses vazamentos continua sendo um desafio significativo no aprendizado federado vertical.
A seguir
Em nosso próximo post, voltaremos nossa atenção para Privacidade de saída, discutindo abordagens que podem impedir que um adversário faça engenharia reversa de qualquer coisa sobre os dados de treinamento de um modelo treinado.