

Esta postagem faz parte de uma série sobre aprendizagem federada que preserva a privacidade. A série é uma colaboração entre o NIST e o Centro de Ética e Inovação de Dados do governo do Reino Unido. Saiba mais e leia todos os posts publicados até o momento em Espaço de colaboração de engenharia de privacidade do NIST ou o blog do CDEI.
Nosso primeira postagem na série introduziu o conceito de aprendizado federado – uma abordagem para treinar modelos de IA em dados distribuídos por meio do compartilhamento modelo Atualizações em vez de dados de treinamento. À primeira vista, o aprendizado federado parece ser perfeito para a privacidade, pois evita completamente o compartilhamento de dados.
No entanto, trabalhos recentes sobre ataques à privacidade mostraram que é possível extrair uma quantidade surpreendente de informações sobre os dados de treinamento, mesmo quando o aprendizado federado é usado. Essas técnicas se enquadram em duas categorias principais: ataques que visam as atualizações de modelo compartilhadas durante o treinamento e ataques que extraem dados do modelo de IA após o término do treinamento.
Esta postagem resume os ataques conhecidos e fornece exemplos recentes da literatura de pesquisa. O objetivo principal do Desafios do Prêmio PETs Reino Unido-EUA foi desenvolver defesas práticas que aumentem as estruturas de aprendizado federado para evitar esses ataques; Postagens futuras desta série descreverão essas defesas em detalhes.
Ataques a atualizações de modelo
No aprendizado federado, cada participante envia Atualizações de modelo em vez de dados brutos de treinamento durante o processo de treinamento. Em nosso exemplo do último post – no qual um consórcio de bancos deseja treinar um modelo de IA para detectar transações fraudulentas – as atualizações do modelo podem consistir em atualizações nos parâmetros do modelo (os componentes do modelo que controlam como suas previsões são feitas) em vez de dados brutos sobre transações financeiras. À primeira vista, as atualizações do modelo podem parecer não transmitir nenhuma informação sobre transações financeiras.
Crédito:
NIST
No entanto, pesquisas recentes demonstraram que muitas vezes é possível extrair dados brutos de treinamento de atualizações de modelo. Um dos primeiros exemplos veio de o trabalho de Hitaj et al., que mostrou que era possível treinar um segundo Modelo de IA para reconstruir dados de treinamento com base em atualizações de modelo. Um exemplo de seus resultados aparece na Figura 1: a linha superior contém dados de treinamento usados para treinar um modelo que reconhece dígitos manuscritos e a linha inferior contém Dados extraídos de atualizações de modelo por seu ataque.

Crédito:
NIST
Trabalhos posteriores de Zhu et al. sugere que esse tipo de ataque é possível para muitos tipos diferentes de modelos e suas atualizações de modelo correspondentes. A Figura 2 contém exemplos de quatro modelos de IA diferentes, mostrando que o ataque é capaz de extrair aproximações quase perfeitas dos dados de treinamento originais das atualizações do modelo.
Como corrigi-lo!
Ataques a atualizações de modelo sugerem que o aprendizado federado sozinho não é uma solução completa para proteger a privacidade durante o processo de treinamento. Muitas defesas contra esses ataques se concentram na proteção das atualizações de modelo durante o treinamento, para que a organização que agrega as atualizações de modelo não tenha acesso a atualizações individuais.
Diz-se frequentemente que as tecnologias de aprimoramento da privacidade que protegem as atualizações do modelo durante o treinamento fornecem Privacidade de entrada – eles impedem que o adversário aprenda qualquer coisa sobre o Entradas (ou seja, as atualizações do modelo) para o sistema. Muitas abordagens para privacidade de entrada, incluindo abordagens usadas nos Desafios do Prêmio PETs Reino Unido-EUA, dependem de aplicações criativas de criptografia. Destacaremos várias dessas soluções ao longo desta série de blogs.
Ataques a modelos treinados
O segunda grande classe de ataques tem como alvo o modelo de IA treinado depois o treinamento terminou. O modelo é a saída do processo de treinamento e geralmente consiste em Parâmetros do modelo que controlam as previsões do modelo. Essa classe de ataques tenta reconstruir os dados de treinamento a partir dos parâmetros do modelo, sem qualquer informação adicional disponível durante o processo de formação. Isso pode parecer um desafio mais difícil, mas pesquisas recentes demonstraram que esses ataques são viáveis.

Crédito:
NIST
Os modelos de IA baseados em aprendizado profundo são particularmente suscetíveis à extração de dados de treinamento de modelos treinados porque as redes neurais profundas parecem memorizar seus dados de treinamento em muitos casos. Os pesquisadores ainda não têm certeza sobre por que essa memorização acontece ou se é estritamente necessário treinar modelos de IA eficazes. Do ponto de vista da privacidade, no entanto, esse tipo de memorização é um problema significativo. Trabalhos recentes de Haim et al. demonstrou a viabilidade de extrair dados de treinamento de um modelo de IA treinado para reconhecer objetos em imagens; um exemplo aparece na Figura 3.

Crédito:
NIST
Crédito:
NIST
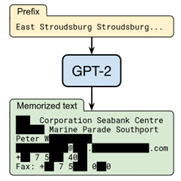
O chalA quantidade de dados de treinamento memorizados parece ser ainda pior para modelos maiores e mais complexos – incluindo modelos populares de linguagem grande (LLMs) como ChatGPT e modelos de geração de imagens como DALL-E. A Figura 4 mostra um exemplo de extração de dados de treinamento de um modelo de geração de imagem usando um ataque desenvolvido por Carlini et al.; A Figura 5 mostra um exemplo de extração de dados de treinamento de um modelo de linguagem grande usando um ataque de Carlini et al.
Como corrigi-lo!
Ataques a modelos treinados mostram que os modelos treinados são vulneráveis, mesmo quando o processo de treinamento está completamente protegido. As defesas contra esses ataques se concentram no controle do conteúdo de informações do próprio modelo treinado, para evitar que ele revele muito sobre os dados de treinamento.
Costuma-se dizer que as tecnologias de aprimoramento da privacidade que protegem o modelo treinado fornecem Privacidade de saída – eles impedem que o adversário aprenda qualquer coisa sobre os dados de treinamento do sistema Saídas (ou seja, o modelo treinado). A abordagem mais abrangente para garantir a privacidade de saída é chamada de Privacidade diferencial, e é objeto de um Série de blogs do NIST e novo Projeto de diretrizes. Muitas das soluções desenvolvidas nos Desafios do Prêmio PETs do Reino Unido-EUA aproveitam a privacidade diferencial para se defender contra ataques ao modelo treinado, que destacaremos mais adiante nesta série de blogs.
Como sempre, esperamos ouvir de você com quaisquer perguntas e comentários. Entre em contato conosco em Animais [at] cdei.gov.uk (animais de estimação[at]cdei[dot]Gov[dot]Reino Unido) ou Privacyeng [at] nist.gov (privacyeng[at]Nist[dot]gov).
A seguir
Em nosso próximo post, apresentaremos uma das principais questões para o aprendizado federado: a distribuição dos dados entre as entidades participantes.