

Em nosso segunda postagem Descrevemos ataques a modelos e os conceitos de Privacidade de entrada e Privacidade de saída. Em nosso última postagem, descrevemos o particionamento horizontal e vertical de dados em sistemas de aprendizado federado que preservam a privacidade (PPFL). Neste post, exploramos o problema de fornecer Privacidade de entrada em sistemas PPFL para a configuração particionada horizontalmente.
Modelos, treinamento e agregação
No aprendizado federado particionado horizontalmente, uma abordagem comum é pedir a cada participante que construa um Atualização do modelo partindo de um Modelo global e treinamento local usando seus próprios dados. Como os dados são particionados horizontalmente, todos os participantes têm dados formatados de forma idêntica e podem treinar modelos que têm formatos idênticos de forma semelhante.
Diferentes formatos de modelo são possíveis, dependendo das técnicas de aprendizado de máquina usadas. Talvez o formato mais comum no aprendizado federado particionado horizontalmente seja uma rede neural, na qual os participantes concordam com um arquitetura de camadas conectadas antes do início do treinamento, e o processo de treinamento se modifica Pesos (ou Parâmetros) dentro das camadas para produzir respostas corretas. Modelos e atualizações de modelos podem ser representados pelos valores desses pesos, geralmente organizados em um vetor ou matriz.
Para combinar
atualizações de modelo, o agregador pode simplesmente calcular a média dos pesos associados às atualizações de modelo dos participantes para obter um modelo global aprimorado. Este algoritmo é chamado de Média federada (FedAvg), e pode ser repetido muitas vezes para treinar um modelo global altamente preciso.
Crédito:
NIST
Privacidade de entrada por meio de agregação segura
O algoritmo FedAvg descrito na última seção não fornece privacidade de entrada — o agregador recebe atualizações de modelo individuais após cada fase de treinamento e pode realizar um dos ataques descritos em nosso post anterior para violar a privacidade dos participantes.
Uma maneira de adicionar privacidade de entrada a esse processo é usar um Agregação segura protocolo, que revela a média das atualizações do modelo para o agregador, mas protege as atualizações individuais. Ocultar atualizações individuais do agregador é uma defesa eficaz contra os “Ataques às Atualizações de Modelo” descritos em nossa postagem anterior.
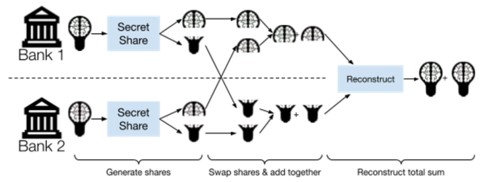
A agregação segura é uma área ativa de pesquisa e muitos algoritmos foram propostos. Um exemplo simples é baseado na ideia criptográfica de Compartilhamento secreto, que permite que um valor secreto seja “dividido” em vários Ações. Cada Compartilhamento individual Revela nada sobre o segredo original; O segredo original só pode ser recuperado combinando todo das ações. Além disso, muitos esquemas de compartilhamento secreto são aditivamente homomórfico, o que significa que a adição pode ser realizada em ações sem combiná-los.
Para usar o compartilhamento secreto para agregação segura, cada participante envia um compartilhamento de sua atualização de modelo para cada participante (mantendo um para si). Em seguida, cada participante soma as ações que recebeu (mais as que detêm para si) e envia o resultado para o agregador. Pelo homomorfismo aditivo do esquema de compartilhamento secreto, o agregador pode combinar os compartilhamentos recebidos para chegar à soma das atualizações do modelo original—mas não tem como acessar as atualizações individuais!
Crédito:
NIST
Essa abordagem exige que os participantes enviem mensagens diretamente uns aos outros e aumenta a quantidade de dados que cada participante deve enviar e receber. Pesquisas recentes nessa área resultaram em abordagens mais eficientes, incluindo sistemas que foram implantado no Google.
No Desafios do Prêmio PETs EUA-Reino Unido, as equipes da Scarlet Pets e da Visa Research incorporaram técnicas de agregação segura como parte de suas soluções vencedoras.
Privacidade de entrada via criptografia homomórfica
Uma abordagem alternativa para adicionar privacidade de entrada ao aprendizado federado particionado horizontalmente é o uso de Criptografia homomórficaem vez de agregação segura. Em geral, as técnicas de criptografia homomórfica permitem a computação em dados criptografados sem ter que descriptografá-los primeiro. Usando criptografia homomórfica, os participantes podem criptografar suas atualizações de modelo usando uma chave de criptografia pública comum e enviar as atualizações criptografadas para o agregador. Se o agregador não tiver acesso à chave secreta correspondente, ele não poderá acessar atualizações individuais.
Para agregar as atualizações do modelo, o agregador pode usar a operação de adição do esquema de criptografia homomórfica para adicionar as atualizações criptografadas — resultando em um único criptografado modelo agregado. Em seguida, o agregador precisa descriptografar o modelo agregado—mas já decidimos que o agregador não deve ter acesso à chave secreta necessária para a descriptografia! A maneira mais fácil de resolver essa desconexão é apresentar outro participante responsável por manter a chave secreta e descriptografar somente modelos agregados. Este participante deve se recusar a descriptografar atualizações individuais e não deve conspirar com o agregador.
A criptografia homomórfica pode ser mais eficiente do que a agregação segura em alguns casos, mas a exigência de um participante adicional que tem a garantia de não conspirar com o agregador dificulta a implantação em muitos cenários. Abordagens alternativas como Criptografia homomórfica de limiar pode eliminar a necessidade de um participante adicional, por exemplo, compartilhando secretamente a chave secreta entre os participantes. No Desafios do Prêmio PETs EUA-Reino Unido, as técnicas nesta categoria foram usadas pelas equipes PPMLHuskies, ILLIDANLAB e MusCAT em suas soluções vencedoras.
Privacidade de entrada por meio de enclaves seguros
Proteger enclaves (também chamado de Ambientes de execução confiáveis ou TEEs) fornecem uma abordagem não criptográfica para a privacidade de entrada que, em vez disso, depende de recursos especiais de segurança do hardware do computador. Por exemplo, o Software Guard Extensions (SGX) da Intel, integrado a muitas CPUs Intel, permite que programas dentro de um enclave calculem dados criptografados sem revelar esses dados ao proprietário da CPU. A incorporação de um enclave seguro em um sistema PPFL permite Untrustedpartes a realizar Confiávelcálculos, que podem simplificar o design do sistema. As abordagens baseadas em enclave também podem melhorar o desempenho, evitando a necessidade de criptografia cara.
Ao contrário das abordagens criptográficas, no entanto, a segurança de um enclave depende da confiabilidade e correção da própria CPU — portanto, os sistemas PPFL que dependem de enclaves seguros exigem a confiança no fabricante da CPU.
A seguir
As técnicas de privacidade de entrada descritas nesta postagem são mais fáceis de aplicar quando os dados são particionados horizontalmente, pois a agregação de modelos pode ser executada por simples adição. No entanto, quando os dados são particionados verticalmente, a agregação é muito mais complexa e diferentes técnicas são necessárias para fornecer privacidade de entrada. A próxima postagem desta série descreverá esse desafio e explorará algumas técnicas comuns para enfrentá-lo.